a) Dependency Injection in Action by Prasanna
b) Learning Google Guice by Hussain Pithawala
Index for Book Dependency Injection in Action by Prasanna:
Chapter 0 - Interesting Links
Chapter 1 - Dependency injection: what's all the hype
Chapter 2 - Time for Injection
Chapter 3 - Investigating DI
Chapter 4 - Building Modular Applications
Chapter 5 - Scope - A Fresh Breath of State
Chapter 6 - More use cases in scoping
Index for Book Learning Google Guice by Hussain Pithawala:
Chapter 4 - Guice in Web Development
- FAQs on Guice
- Google Guice Group
- Link to java doc for
FactoryModuleBuilder - In Guice, the default scope is Prototype. In Spring, the default scope of a Bean is Singleton.
- Guice, Dagger, Spring
- Bean scopes in Spring. Official Doc.
- Consider the following architecture for the service:
 - Let the three objects responsible for these actions be:
- Let the three objects responsible for these actions be: Emailer, InternetRelay, RecipientInbox. Each object is a client
of the next. Emailer uses the InternetRelay as a service to send email, and in turn, the InternetRelay uses the
RecipientInbox
as a service to deliver sent mail. - There's value in decomposing our services into objects. Take the
Emailer for example. The Emailer will require a text editor to type-in the
email. This logic could be added in the Emailer class itself, but it is better to create a new TextEditor. Pulling this functionality into its
own class has the following advantages: a) Our
Emailer is not cluttered with distracting code meant for text manipulation. b) We can reuse the
TextEditor component in other scenarios (say, a calendar or note-taking application) without much additional coding. c) If someone else has written a general-purpose text-editing component, we can make use of it rather than writing one from scratch
- This principle is important because it highlights the relationship between one object and other objects it uses to perform its function: an object depends on its services in order to perform its function. In this example that we are talking about, the
Emailer class depends upon a TextEditor,
SpellChecker, and a Dictionary to perform its functions. Hence these 3 classes are the dependencies of the Emailer class.
In other words, the Emailer class is a client of its dependencies. - The dependencies of the
Emailer class may have dependencies of their own and this relationship carries on transitively. This composite system of
dependencies is known as the object graph. - Hence we get the following definitions:
a)
Service
: An object that performs a well-defined function when it is called.b)
Client
: Any consumer of a service. A client calls a service to perform a well-understood function.c)
Dependency
: A specific service that is required by another object to fulfill its function.d)
Dependent
: A client object that needs a dependency (or dependencies) in order to perform its function.e)
Dependency Injection
: DI is the study of reliably and efficiently building such object graphs and the strategies, patterns, and best practices therein.Emailer which is composed of a SpellChecker, this might be the first thing that you come up with:
SpellChecker was in-fact being called when you used the send
method to send an email. One way to do this would be to create a MockSpellCheckerand make Emailer use that:
Emailer class has. This effectively makes the
Emailer class untestable. - There is another problem with this approach. You cannot create objects of the same
Emailer class with different functionality. For instance, suppose you
were writing an email client for the english language, then you would do something like:
Emailer class for the french language, you would have to create a completely new Emailer class. We need
another system where instead of the dependent creating its own dependencies, it has them provided externally. Emailer creating its own SpellChecker, we can add a method that accepts a SpellChecker.
SpellChecker with a version of our own, and thus we can use the MockSpellChecker that we created above to
now test the functionality of the Emailer class. Similarly, we can also substitute the SpellChecker with another spell checker easily now.
SpellChecker manually. At the time of construction of the Emailer class, we are manually setting the
dependency. Hence, this is also sometimes referred to as construction by hand. - The above code was an example of setter injection. You can also do a constructor injection by passing in the dependency during the construction of the
Emailer class itself. The advantage of following this approach is that it makes the dependency between the two classes explicit. You cannot create an
Emailer class without creating a SpellChecker class. And thus it reduces the chances of someone forgetting to set the dependency on the object.
Problems with construction-by-hand
: The problem with this technique is that the burden of knowing how to create the object graph is placed on the client of the service. In this case, it is theEmailer class that must set up its dependency, SpellChecker, either through constructor or through setter injection. Also, if the same object is
being
used in multiple places, then you need to repeat the code of wiring together the object in all the places. If you decide to change the dependency graph in the future, you
will have to go to all the places and make the change yourself. - Another problem is the fact that users need to know how object graphs are wired internally. This violates the principle of encapsulation and becomes problematic when dealing with code that is used by many clients, who really shouldn't have to care about the internals of their dependencies in order to use them.
Emailer.
By adding a level of abstraction (the Factory pattern), we have separated the code using the Emailer from the code that creates the Emailer. This
leaves client code clean and concise. This becomes even more useful when the object graph of the created object is even more complex.
Emailer code is still using the same constructor injection it was using previously. So we can still test the Emailer
class as we were previously. Problems with using Factory Pattern
: Testing the internals of the object returned from the factory becomes difficult unless the factory has explicitly provided capabilities to test it. What do I mean by that? This client does not know anything aboutEmailer's internals; instead, it depends on a Factory. In one of the previous scenarios, we were able to swap out the
SpellChecker being injected into the class with a MockSpellChecker of our own. But that will not be possible in this case. - Another issue is that if you are going with Factory Pattern then you will have to create a new method for every variation of every service. That is a lot of code to test and maintain. If you decided that you wanted to replace the
AddressBook with PhoneAndAddressBook, you will have to go through all the
methods in the factory and make the substitution. Plus there might be many dependencies that are common across different types of Emailer objects but which you still
have to specify separately for each new method that you add to the factory. One way to get around this is to use a 'general' factory that first creates a common version of
the object and then use that intermediate object to set any specific fields on it. But this again leads to code that is difficult to test.
- This is what it would look like:
Emailer emailer = (Emailer) new ServiceLocator().get("Emailer"); - Since all the locator needs is a key, a Service Locator acts as a factory that can return any kind of service. Compare this to the EmailerFactory class where it was returning only one type of object - namely Emailer.
- The Java Naming and Directory Interface (JNDI) is a good example of a Service Locator pattern. It is often used by application servers to register resources at start time and later by deployed applications to look them up. Web applications typically use JNDI to look up data sources in this manner.
- An example of gettig a different object:
Emailer emailer = (Emailer) new ServiceLocator().get("JapaneseEmailerWithPhoneAndEmail");
Problems with using Service Locator Pattern
: Being a kind of Factory, Service Locators suffer from the same problems of testability and shared state. The keys used to identify a service are opaque and can be confusing to work with. The practice of embedding information about the service within its identifier (namely, "JapaneseEmailerWithPhoneAndEmail") is also verbose and places too much emphasis on arbitrary conventions.- In case of DI, the task of creating, assembling, and wiring the dependencies into an object graph is performed by an external framework known as a dependency injection framework or simply a dependency injector. The control over the construction, wiring, and assembly of an object graph no loger resides with the clients or services themselves. This is also known as the Inversion of Control.
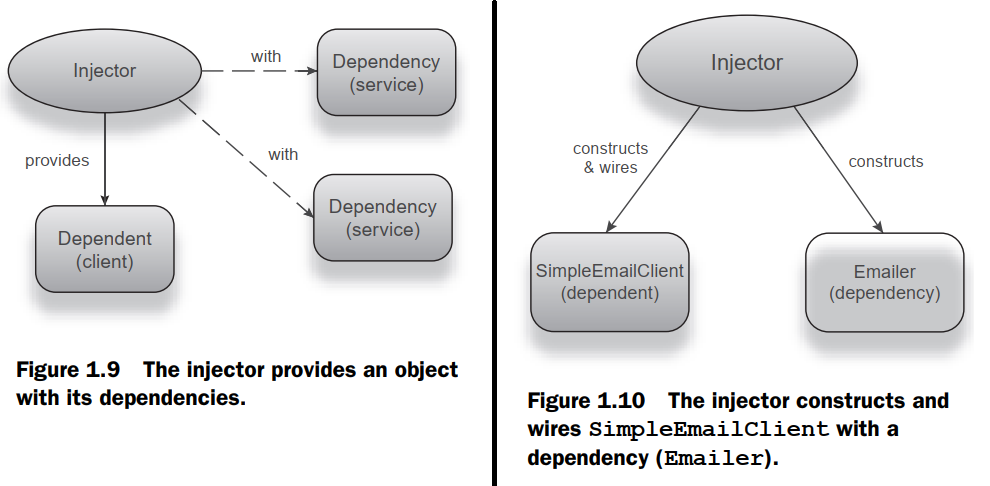
- This highlights the separation of infrastructure code (meant for wiring and construction) from application code (the core purpose of a service).
- This is an example of using Guice for injection:
@Inject annotation on the Emailer and the SpellChecker classes in order to
get the code to compile properly. If you remove this annotation, from either of the classes, you get the following error: "Could not find a suitable constructor in
Chapter2._1_Basics.SpellChecker. Classes must have either one (and only one) constructor annotated with @Inject or a zero-argument constructor that is not private." - The
@Inject annotation is supposed to tell Guice which constructor to use when creating the object, and consequently what it's dependencies are. - In this particular line:
Emailer emailer = Guice.createInjector().getInstance(Emailer.class); you are doing something similar to what we did in the Service
Locator pattern, the difference being now we are using a class type to get an object as the key, instead of directly using a string. In a sense the injector is an automated,
all-purpose service locator prepackaged for convenience.
@Inject annotation was configure the injector by telling it which constructor to use and hence what the
dependencies of the object are. If you had been using Spring, you would do the same thing by using @Component and @Autowired combination. - There are multiple ways in which you can configure the injector:
a) Using an XML Configuration File
b) Invoking into a programmatic API
c) Using an injection-oriented DSL
d) By inference; that is, implicitly from the structure of classes
e) By inference from annotated source code
BeanFactory refers to the Spring dependency injector. The call to getBean() is analogous to the original call to getInstance().
Both return an instance of Emailer. The FileSystemXmlApplicationContext is a special type of BeanFactory. There are other kinds of
application contexts available for use as well. They are mentioned on this link on Baeldung. - The file email.xml contains the configuration required for Spring's injector to provide us with an emailer correctly wired with its dependencies.
Module interface, or by
extending the AbstractModule class. - Guice is able to automatically inject Concrete Class with either a public no argument constructor or a constructor with @Inject without any specific defined binding in your module but when it comes to Interfaces you have to define the necessary bindings. Source on SO. This is what the module class would look like with the bindings defined:
createInjector method. Without
this it does not work.
AbstractModule, this is what the module class would look like. And instead of passing in the
new EmailModule() as you did above, you would now be passing in new EmailAbstractModule().
ClassPathXmlApplicationContext, instead of the FileSystemXmlApplicationContext that we used previously above.
Note that you also had to add this in Facets in Intellij, because it was giving you a warning. Note the folder structure as well. The reason for highlighting the folder
structure is so that you can notice the usage of class path related stuff. See how paths are being used in
new ClassPathXmlApplicationContext("email-actual-autowire-config.xml") and <context:component-scan base-package="_1_Basics"/> and relate it to
the folder structure being used. The same warning that you get when you add an XML configuration file, you also get when you annotate a java class with
@Configuration. Both, XML files and @Configuration are different but equivalent ways of telling Spring how you want to setup the beans.
 - The three application contexts that were introduced above can be seen here:
- The three application contexts that were introduced above can be seen here:
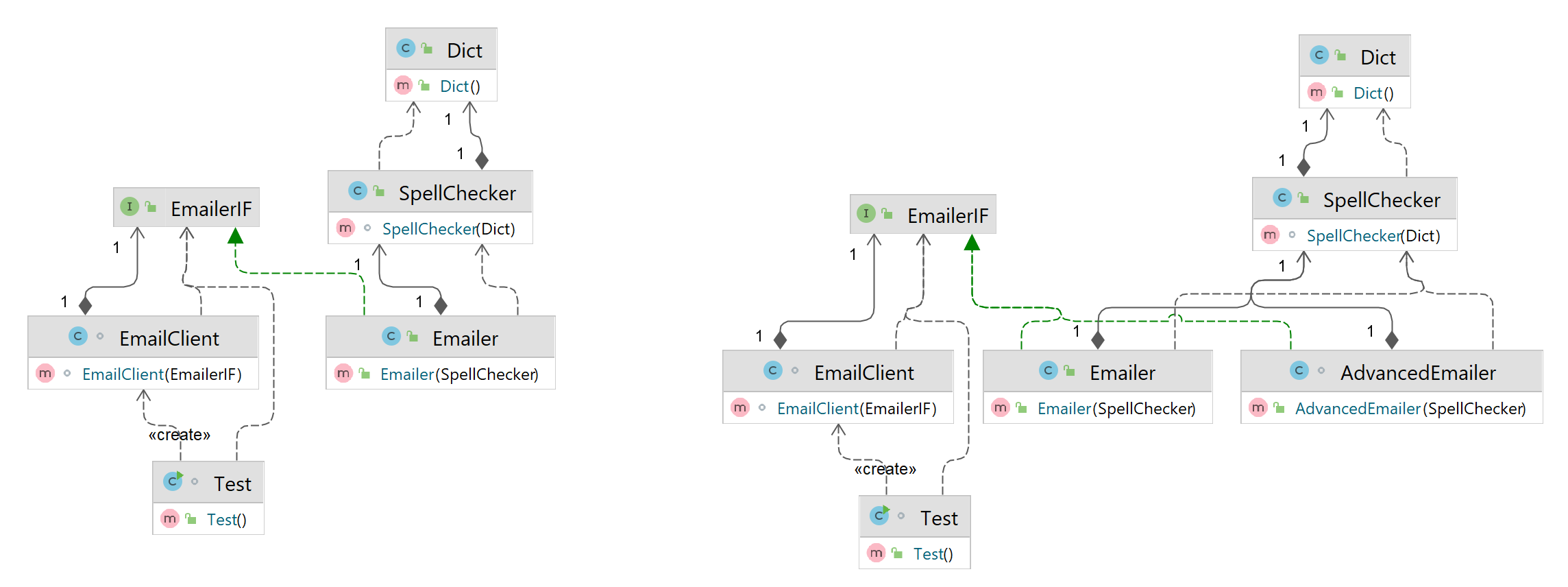
- In the Guice example that we saw above, there is a single implementation of the EmailerIF that we are using to inject in as a dependency, namely the Emailer class. But we might have multiple implemnetations of the same interface and we may want to conditionally inject different implementations depending on our requirements. For example, on the right side, we have two implementations of the EmailerIF, Emailer and AdvancedEmailer. So when we create an EmailClient, we might might want to choose either of the implementations, Emailer or AdvancedEmailer. So how do you tell your injector which of these two dependencies you want to use? This is the question we will be trying to answer here.
 - Then depending on the type of Emailer that we are trying to create, we can configure the xml as follows:
- Then depending on the type of Emailer that we are trying to create, we can configure the xml as follows:
Drawbacks of this method
:a) A misspelled key that maps to no valid service can be difficult to detect until well into the runtime of the program. If you are working with a statically typed language like Java, this is a poor sacrifice to have to make. These languages are supposed to offer guarantees around type validity at compile time. Ideally, one should not have to wait until runtime to detect problems in key bindings. Intellij does not warn you about these kinds of errors, and they appear only during runtime.
b) In your injector configuration there is no way to determine the type of a binding if all you have is a string key. Without starting up the injector and inspecting the specific instance for a key, it is hard to determine what type the key is bound to. But do note that Intellij does provide you with some level of static checking in order to minimize this kind of issue. For example suppose you passed in an incorrect class Dict_2 instead of Dict, Intellij would give you a compile error.
- All the stuff with the XML configuration that we did in the above section using Spring, we can also do using simple annotations. We make use of the
@Configuration and @Bean annotations for this. The objective is still the same - pass in different implementations of the SpellChecker class
for the specific implementations for the Emailer. But this time without using XML. - First we need to define a configuration class that would be equivalent to defining the XML file in the previous approach. The
@Configuration annotation
indicates that the class can be used by the Spring IoC container as a source of bean definitions. It indicates that a class declares one or more @Bean methods
and may be processed by the Spring container to generate bean definitions and service requests for those beans at runtime. - The
@Bean annotation tells Spring that a method annotated with @Bean will return an object that should be registered as a bean in the Spring
application context. See this link on Tutorials Point for a good explanation.
We aren't doing anything special, all we have done is convert the XML bindings into code.
- If you had just a single object of a particular type, you could have fetched the object using the type of the object, as we are doing with the EnglishSpellChecker in the below example. For other cases, you would have to fall back to using the String keys instead.
Drawbacks of this method
:a) Like we saw, if we use types, we cannot distinguish between different implementations of the same service.
- GuiceTM embodies the use of type/annotation combinatorial keys and was probably the first library to use this strategy.
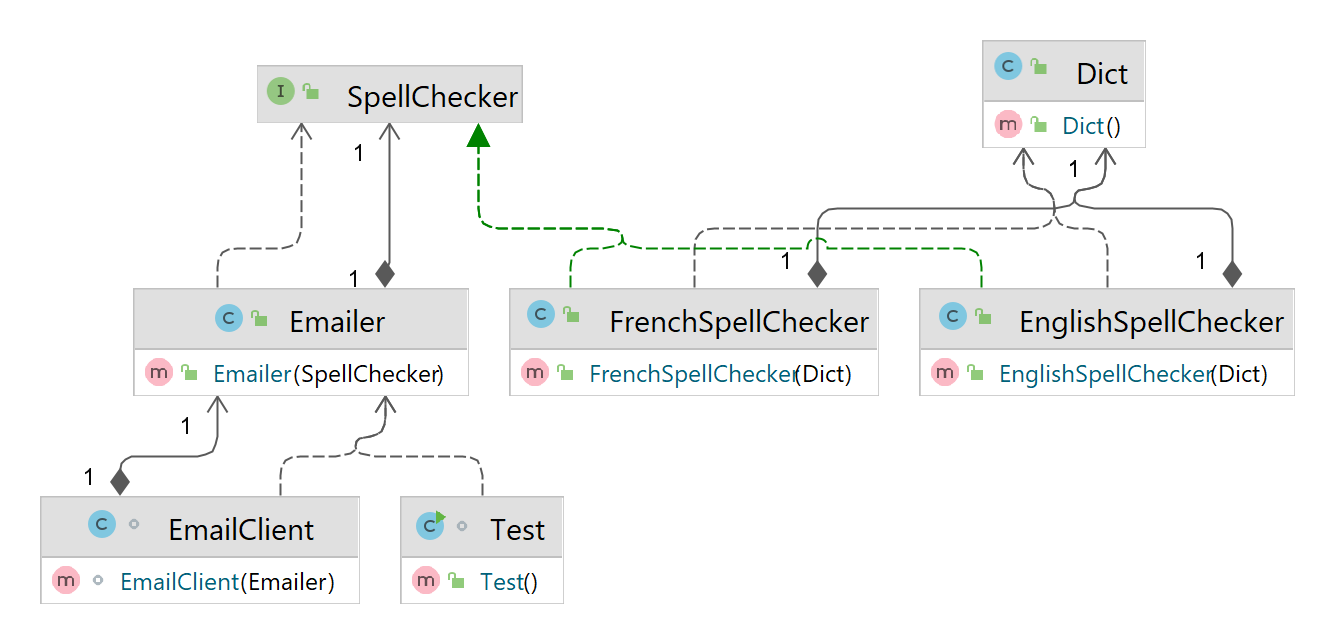
- Suppose this is the object graph that we are going to create. As we can see in the diagram, FrenchEmailer and EnglishEmailer both require the dependency SpellChecker. But there are two different implementations available: FrenchSpellChecker and EnglishSpellChecker. We want the EnglishSpellChecker to be injected into the EnglishEmailer class and the FrenchSpellChecker into the FrenchEmailer class.
- The way we are going to do this is through the use of annotations. At the point where we are injecting SpellChecker type into the EnglishEmailer for eg., we will annotate that injection with a custom annotation
@English that we have created. Then we are going to tell Guice that - hey, whenever you see a dependency
that requires the SpellChecker object, and has been annotated with @English, you should inject the EnglishSpellChecker exclusively. In the same manner,
we are going to do for the french side as well.
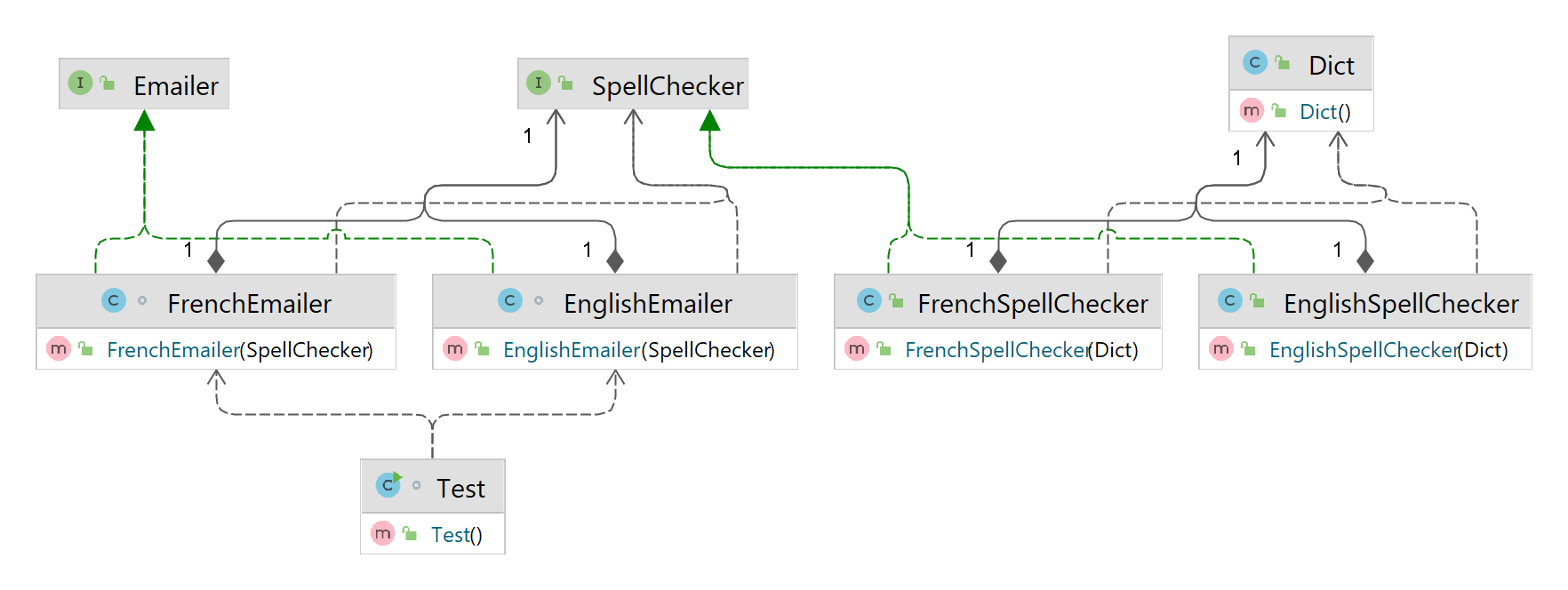 Step 1) We create custom annotations that we are going to make use of.
Step 1) We create custom annotations that we are going to make use of.
@English annotation. Doesn't this mean EnglishEmailer is tightly coupled to English spellcheckers? The answer is a surprising no. To understand why,
consider the following altered injector configuration: bind(SpellChecker.class).annotatedWith(English.class).to(FrenchSpellChecker.class);. Here, we've changed
the service implementation bound to the combinatorial key [SpellChecker.class, English.class] so that any dependent referring to an @English annotated
SpellChecker will actually receive an implementation of type FrenchSpellChecker. There are no errors, and EnglishEmailer is unaware of
any change and more importantly unaffected by any change. No client code needs to change, and we were able to alter configuration transparently. So they aren't really
tightly coupled.
1) Constructor Injection
:- A constructor's purpose is to perform initial setup work on the instance being constructed, using provided arguments as necessary. This setup work may be wiring of dependencies (what we are typically interested in) or some computation that is necessary prior to the object's use.
- A constructor has restrictions that differentiate it from a normal method:
a) Cannot (does not) return anything
b) Must complete before an instance is considered fully constructed
c) Can initialize
final fields, whereas a method cannot d) Can be called only once per instance
e) Cannot be given an arbitrary name - in general, it is named after the class
2) Setter Injection
:- In case of setter injection, the wiring takes place after the instance has been fully constructed.
- The setter injection differs based on the DI framework that you are using. In the case of Spring, a setter directly refers to a property on the object and is set via the
<property> XML element. - This is what the class in the case of Setter Injection would look like. Also note that the setters in this case need to be declared as
public.
<property> tags. This ordering is unique to the XML configuration
mechanism and is not available with autowiring. @Inject.
Interestingly, even if you remove the annotation from the method, the code still works. So the annotations are not mandatory? - The order in which these setters are called is undefined, unlike with Spring's XML configuration.
- Another thing to keep in mind is that these setters are called by Guice itself, immediately after the constructor has been executed completely. So when you use this object, the object that you get finally is the fully-formed object. At no point do you have to call the setters manually yourself in order to set these dependencies on the object. The framework does that for you automatically like magic. Of course, nothing is stopping you from calling the setters yourself if you want to and set in a different object for these dependencies, but you do not HAVE to. And that is the important thing to keep in mind. All of the injection is happening behind the scenes, without you having to do things like:
Amplifier amp = new Amplifier(); amp.setGuitar(new Guitar()); amp.setSpeaker(new Speaker()) etc. before having to use the amp object.
- Guice does not place any restrictions on the name or visibility of setters either. So you can hide them from accidental misuse. In the above example, you could have declared the set up method as
@Inject private void setUp(...), and the code would STILL have worked. This is because Guice takes use of reflection, and
reflection can do very weird things. But is this a good thing to do, declaring methods as private and using @Inject on top of that? I don't know.
3) Interface Injection
:- Interface injection is the same as setter injection except that each setter is housed in its own interface. This design is not commonly used. However, some of the ideas behind interface injection form the basis of important design patterns and solutions to several knotty design problems.
4) Method Decoration
:- When they are called, these methods return an injector-provided value instead of their normal value. This process is called decorating the method and gets its name from the Decorator pattern. It is useful if you want to make a Factory out of an arbitrary method on your object.
- The problem that we are trying to solve is this. We want the Candy class to be wired and created by the injector. Hence, the way that we are manually creating and returning the object is not sufficient.
5) Field Injection
:- You can also wire dependencies directly into the fields.
@Inject tells the injector to wire dependencies directly to them when BrewingVat is requested.
This happens after the class's constructor has completed and before any annotated setters are called for setter injection. - Without the ability to set dependencies (whether mocked or real) for testing, unit tests cannot be relied on to indicate the validity of code. It is also not possible to declare field-injected fields immutable, since they are set post construction. So, while field injection is nice and compact (and often good for examples), it has little worth in practice.
1) Constructor vs Setter Injection
:- The merits and demerits of using either constructor or setter injection are the same as those for setting fields by either constructor or setters.
- An important practice regards the state of fields once set. In most cases we want fields to be set once (at the time the object is created) and never modified again. This means not only that the dependent can rely on its dependencies throughout its life but also that they are ready for use right away. Such fields are said to be immutable. The basic idea is that once the dependency object graph has been created, the graph is fixed, and no changes can be done to the graph whatsoever.
- If you think of private member variables as a spatial form of encapsulation, then immutability is a form of temporal encapsulation, that is, unchanging with respect to time. With respect to dependency injection, this can be thought of as freezing a completely formed object graph. Constructor injection affords us the ability to create immutable dependencies by declaring fields as
final. - Immutability is essential in application programming. Unfortunately, it is not available using setter injection. Because setter methods are no different from ordinary methods, a compiler can make no guarantees about the one-call-per-instance restriction that is needed to ensure field immutability.
- A second advantage to using constructor injection is that the object becomes fully available for use immediately. I.e. if a dependency were not provided, either in the configuration, or in a unit test, a compiler error would have alerted us to a misconfiguration immediately. Contrast this with a setter injection. Suppose you forgot to add
@Inject on a setter, you wouldn't realize that you missed it unless you tried to execute some method on the injected object, ultimately resulting in a NPE
(because the dependency was never set by the injector). Similarly, if you were writing tests for a class using constructor injection, you would just have to call the
constructor, and would be enough for the setUp(). But in the case of using setter injection, you need to call the constructor, and then separately have to call
each of the setters on the object to set the required dependencies before being able to run any of the tests. Not cool. - One problem with the constructor injection though is that if your object requires multiple dependencies which are of the same type, it is easy to get the order of the dependencies mixed up and end up with a malformed object. The error goes completely undetected. Imagine a case where you have like 8 string args in a constructor. Compare this to if we were using setter injection, and it would have been very easy to give meaningful names to the setters, thus minimizing any chances of such errors.
2) The Constructor Pyramid Problem
:- When you have different object graph permutations of the same object, the number of constructors can get out of hand, which becomes confusing when it comes to deciding which constructor to make use of.
- Consider the following Amphibian class:
- If you find yourself encountering the pyramid problem often, you should ask serious questions about your design befor pronouncing setter injection as a mitigant.
3) The Circular Reference Problem
:- The problem becomes when you are trying to create an object graph that looks like this. The constructor for a Symbiote requires a Host, and the constructor for Host requires a Symbiote. Both of them refer to the same instances of each other. Syntactically, there is no conceivable way to construct these objects so that circularity is satisfied with constructor wiring alone. If you decide to construct Host first, it requires a Symbiote as dependency to be valid. So you are forced to construct Symbiote first; however, the same issue resides with Symbiote.
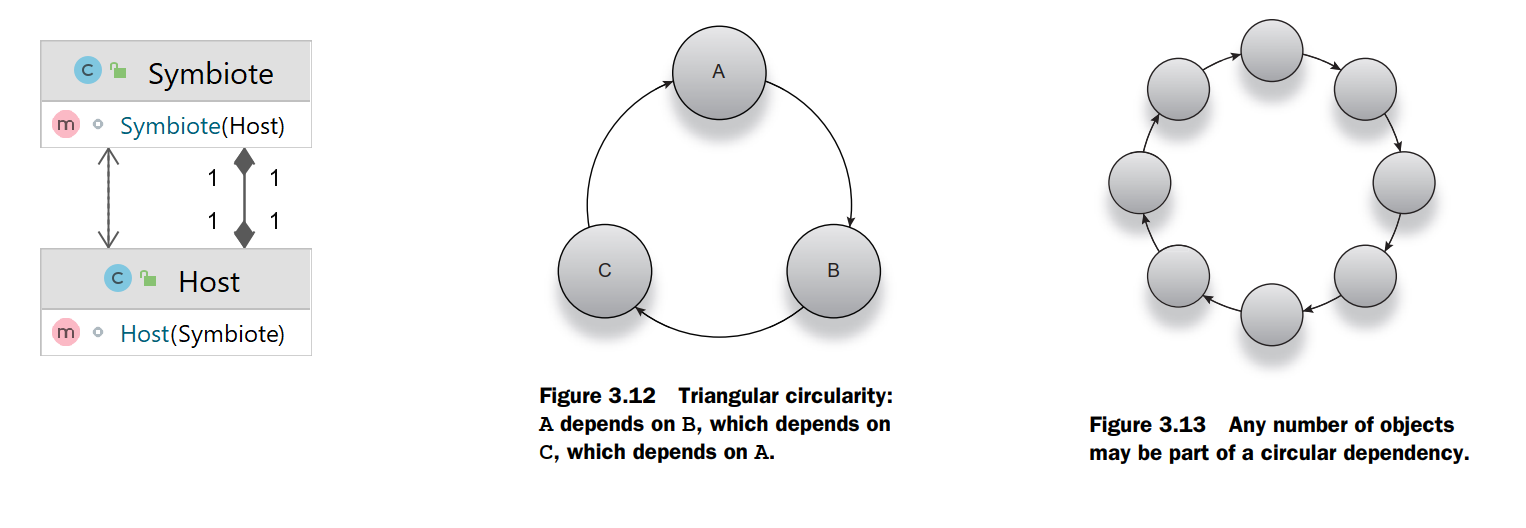 - This classic chicken-and-egg scenario is called the circular reference problem. The triangle one is more commonly seen in the wild.
- This classic chicken-and-egg scenario is called the circular reference problem. The triangle one is more commonly seen in the wild. - There are two possible solutions to this, using setter or constructor injection. This link on baeldung explains how to solve this issue in the case of Spring.
- Refer this page on Guice docs to read about cyclical dependencies and how to get around them. This SO answer goes into detail about how Guice works to resolve circular dependency issues. This answer on SO explains the scenarios in which Spring creates proxies.
Spring - using setter injection to solve the issue
:- The setter injection solution is to just switch to setter injection. When the injector starts up, both host and symbiote object graphs are constructed via their nullary (zero-argument) constructors and then wired by setter to reference each other. The drawback of this approach is that the dependencies can now no longer be declared as
final.
Spring - using constructor injection to solve the issue
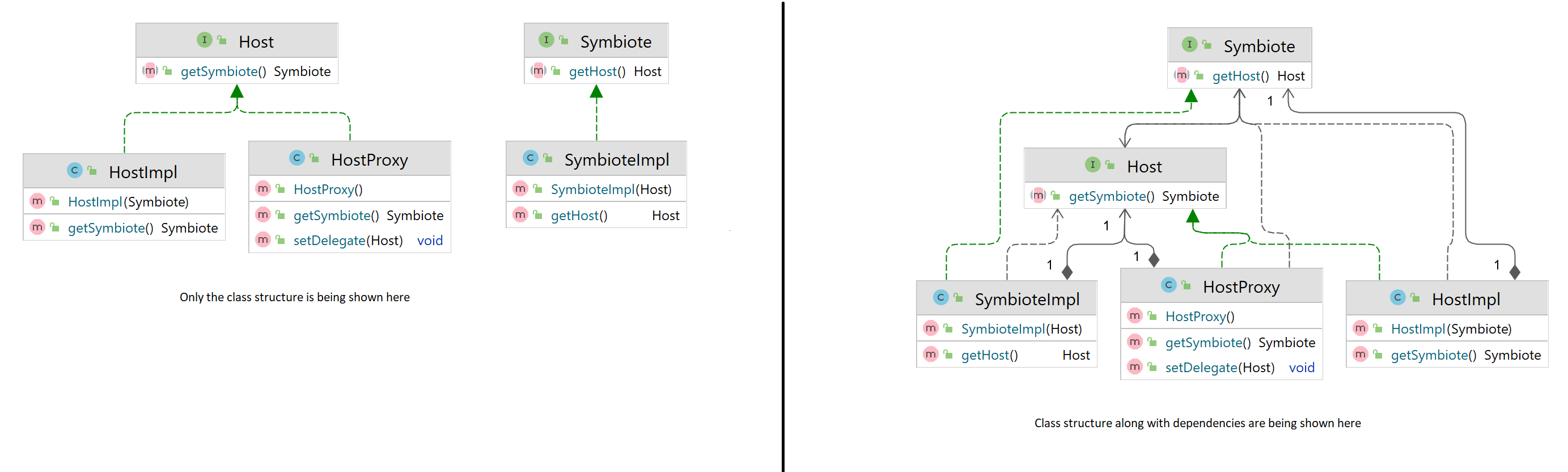
:- Solving this by using constructor injection requires us to use a proxy object. First we decouple the Host and the Symbiote so that they use interfaces. The concrete classes HostImpl and SymbioteImpl now have dependency on the interfaces instead of the concrete classes. We have introduced a new class HostProxy that implements the same interface that the HostImpl implements. Unlike HostImpl, HostProxy has a zero-dependency constructor. This means we can now carry out the following sequence of steps in order to form the object graph:
a) Construct HostProxy
b) Construct SymbioteImpl using the instance of HostProxy created in step 1
c) Construct HostImpl using the SymbioteImpl created in step 2
d) Call the setter setDelegate on HostProxy by passing in the HostImpl created in step 3
 - (From the gang of four book) Delegation is basically defined as follows: Delegation is a way of making composition as powerful for reuse as inheritance. In delegation, two
objects are involved in handling a request: a receiving object delegates operations to its delegate. This is analogous to subclasses deferring requests to parent
classes.
- (From the gang of four book) Delegation is basically defined as follows: Delegation is a way of making composition as powerful for reuse as inheritance. In delegation, two
objects are involved in handling a request: a receiving object delegates operations to its delegate. This is analogous to subclasses deferring requests to parent
classes. - For example, instead of making class Window a subclass of Rectangle (because windows happen to be rectangular), the Window class might reuse the behavior of Rectangle by keeping a Rectangle instance variable and delegating Rectangle-specific behavior to it. In other words, instead of a Window being a Rectangle, it would have a Rectangle. Window must now forward requests to its Rectangle instance explicitly, whereas before it would have inherited those operations.
- This is the same concept that we are also using over here. The HostProxy is supposed to simply delegate the requests that it gets for performing operations on the Host object to the actual implementation of the Host type (HostImpl) that it has saved.
- Question: Well even though the Host hostProxy field on SymbioteImpl has been marked as
final, the setDelegate method allows you
to change the underlying reference of Host as and when you like. So where is the immutability that was promised? Hmm? - This is what the code looks like when we are using Constructor Injection in order to solve the circular dependency issue:
Spring - using annotations to solve the issue
:- You can get Spring to create the proxies automatically by using the
@Lazy annotation. - This is what the code looks like in this scenario:
Guice - using annotations to solve the issue
:- In the case of Guice, all you need to do is extract the classes to an interface of its own (a step that we have already done) and then bind the classes to their resp. implementation in the Guice module. The Guice injector automatically provides the proxy in the middle. We can also trust the injector to work out the correct order of construction. We don't deal directly with proxies or setter injection or any other infrastructure concern.
4) The In-Construction Problem
:- One close relative of the circular reference problem that we saw above is where initialization logic requires a dependency that is not yet ready for use. What this typically means is that a circular reference was solved with a proxy, which has not yet been wired with its delegate.
- This example code is building up on the example that we discussed in the circular dependency problem. Since Host has been proxied but does not yet hold a valid reference to its delegate, it has no way of passing through calls to the dependency. This is the in-construction problem in a nutshell. The only recourse in such cases is setter injection.
- Example code here is in Spring using the same config xml file that we used above.
5) Constructor Injection and Object Validity
:- If you use setter injection, you require a lot of upfront work in order to make sure that all the dependencies have been injected properly. For instance, suppose we were trying to set up Spring to wire in the following objects:
a) We have to remember to set both of the setters manually by using the
property tags. b) We have an init method defined in the class, that needs to be manually set up as well by using the
init-method tag. c) Objects in Spring are Singletons by default. This means that other multiple threads are concurrently accessing unsafeObject. While the injector is itself safe to concurrent accesses of this sort, UnsafeObject may not be. The Java Memory Model makes no guarantees about the visibility of non-
final,
non-volatile fields across threads. To fix this, you can remove the concept of shared visibility, so an instance is exposed to only a single thread. We do this
by scoping each bean to a prototype. This tells the injector to create a new instance of UnsafeObject each time it is needed. Now there are no concurrent
accesses to UnsafeObject. Notice that you are forced to mark both dependencies with scope="prototype" as well. Otherwise they may be shared
underneath. - You were also confused about the order in which the methods would be called:
Inside the UnsafeObject constructor -> Inside the constructor for Shady -> Inside the constructor for Slippery -> Inside the setShady method -> Inside the setSlippery method -> Inside the init method (init method is called only after the setter dependencies have been set)
- We can solve all of these issues in one go by simply using Constructor Injection. There is only one way to construct it, since it exposes only the one constructor. Both dependencies are declared
final, making them safely published and thus guaranteed to be visible to all threads. Initialization is done at the end of the
constructor. And init() is now private, so it can't accidentally be called after construction.
- Consider the following example. Granny is given one apple when she comes into existence. Upon being told to eat(), she consumes that apple but is still hungry. The apple cannot be consumed again since it is already gone. In other words, the state of the dependency has changed and it is no longer usable. Apple is short-lived, while Granny is long-lived, and on each use (every time she eats), she needs a new Apple.
Provider pattern that we are going to look at next.
Provider<T>Using Provider pattern with Guice
:- This is an example of how we would set the Provider pattern up. Note that no injector configuration apart from this was required in order to set this up. Guice is clever enough to work out how to give you an Apple provider.
a) A Provider is unique (and specific) to the type of object it provides. This means you don't do any downcasting on a
get() as you might do with a Service
Locator. b) A Provider's only purpose is to provide scoped instances of a dependency. Therefore, it has just the one method,
get(). Guice provides Providers out of the
box for all bound types. - This is what the
Provider interface in Guice looks like. Method get() is fairly straightforward: it says get me an instance of
T. This may or may not be a new instance depending on the scope of T. For example, if the key is bound as a singleton, the same instance is returned
every time.
Using Provider pattern with Spring
:- Spring does not have a Provider class out of the box. But we can create a Provider of our own and use it pretty much in the same way that we did with Guice.
prototype in order for a new instance of
Apple to be returned everytime. Note that for the AppleProvider class, we did not have to explicitly tell Spring to wire-in the injector. Spring was able to
look at the BeanFactoryAware interface and able to inject it automatically. BeanFactoryAware is an example of the Interface Injection that we
looked at above in Interface Injection section.
@Assisted- This SO Link explains Assisted Inject.
- Consider the following example. The Deliverer instance that we want to create has 3 dependencies. Suppose EmailService is supposed to be injected by the injector, whereas the other two dependencies, NewsLetter and date need to supplied by the instance's creator.
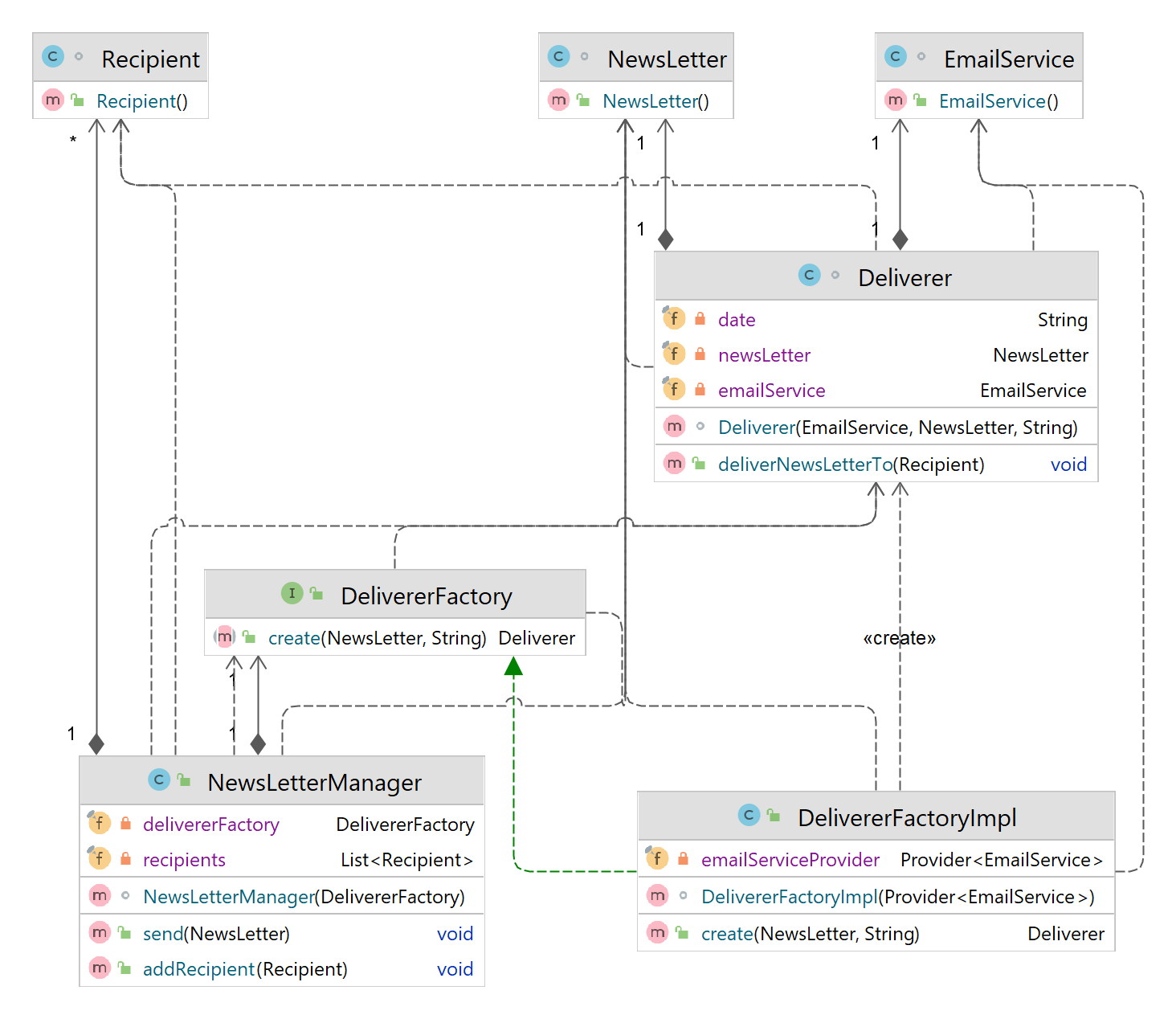 - In such a case, the standard solution is to write a factory that helps Guice build the objects. NewsLetterManager needs an instance of Deliverer in order to
send the newsletter to its list of recipients. We cannot create the Deliverer object in the way that we have been doing so far because we need to pass in two args to
the object ourselves. We are doing this by creating a factory, DelivererFactory. NewsLetterManger makes the use of DelivererFactoryImpl in order to
obtain an instance of Deliverer.
- In such a case, the standard solution is to write a factory that helps Guice build the objects. NewsLetterManager needs an instance of Deliverer in order to
send the newsletter to its list of recipients. We cannot create the Deliverer object in the way that we have been doing so far because we need to pass in two args to
the object ourselves. We are doing this by creating a factory, DelivererFactory. NewsLetterManger makes the use of DelivererFactoryImpl in order to
obtain an instance of Deliverer.
@Assisted and the constructor will have to be annotated with @Inject. This Factory will have to be
injected into the NewsLetterManager constructor because that is where we are originally making use of the Deliverer class. We call create there, which
goes to the Deliverer.Factory interface, from where Guice automatically creates an implementation of the Factory for us. This is by telling Guice to do so in the
GuiceModule class. Guice creates the implementation of the Factory and returns back a fully-formed Deliverer object for us.
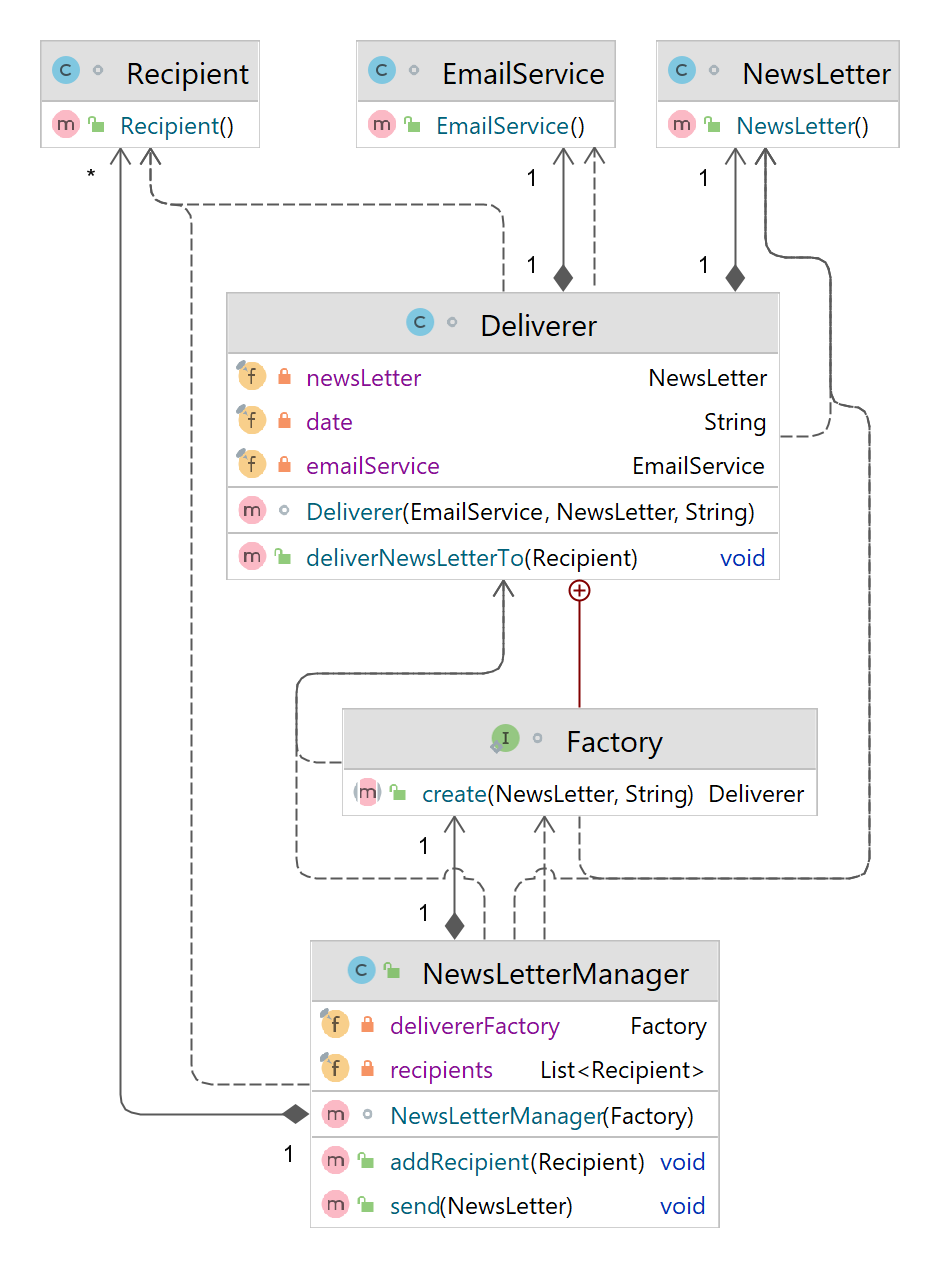 - So much talking. Does it even help clear things up? This is what the code looks like.
- So much talking. Does it even help clear things up? This is what the code looks like.
@Assisted with multiple args that are of the same type - Using @NamedString param to the constructor of the Deliverer class called name that would also
have to be provided by the instance's creator (just like the date param for exmaple). We would then need to add this param to the Factory interface. But this
won't work. If we try to run the code, we will get an error. - This SO post explains the problem and the solution. Java Doc for
FactoryModuleBuilder. - You get the following error when you do this:
String annotated with @Assisted(value="") was bound multiple times. Learn more at this link. - The types of the factory method's parameters must be distinct. To use multiple parameters of the same type, use a named
@Assisted annotation to disambiguate
the parameters. The names must be applied to the factory method's parameters and to the concrete type's constructor parameters. Hence the class would now look something like
this. The places where we changed the code are commented with // changed here.
@Assisted?a) Is it possible and how to do Assisted Injection in Spring?
b) Partial auto-wire Spring prototype bean with runtime determined constructor arguments
- Here I am following a slightly different approach compared to the above two links, but one that we had done previously in the
Provider approach for Spring
here. The same BeanFactoryAware method is being used to create a Factory that can form the Deliverer object for
us consisting partially of dependencies injected from the container, and runtime values added by us.
@Provides annotation vs the Provider class- Refer the Gang of Four book for the Builder pattern. Refer the text for this.
- Goes over how you can use the Adapter Pattern to inject dependencies into third-party code??
a) A logical grouping of data and related operations
b) An instance of a class of things
c) A component with specific responsibilities
- An object is all these things, but it is also a building block for programs. And as such, the design of objects is paramount to the design of programs themselves. Classes should have a specific, well-defined purpose and stay within clearly defined boundaries. Each object has its area of concern. Good design keeps those concerns separated.
- Similarly, logic dealing with different business areas can be separated vertically. Checking spelling and editing text are two core parts of any email application. Both deal with application logic and are thus focused on business purpose. However, neither is especially related to the other. In other words, separating logic by area of concern is a good practice.
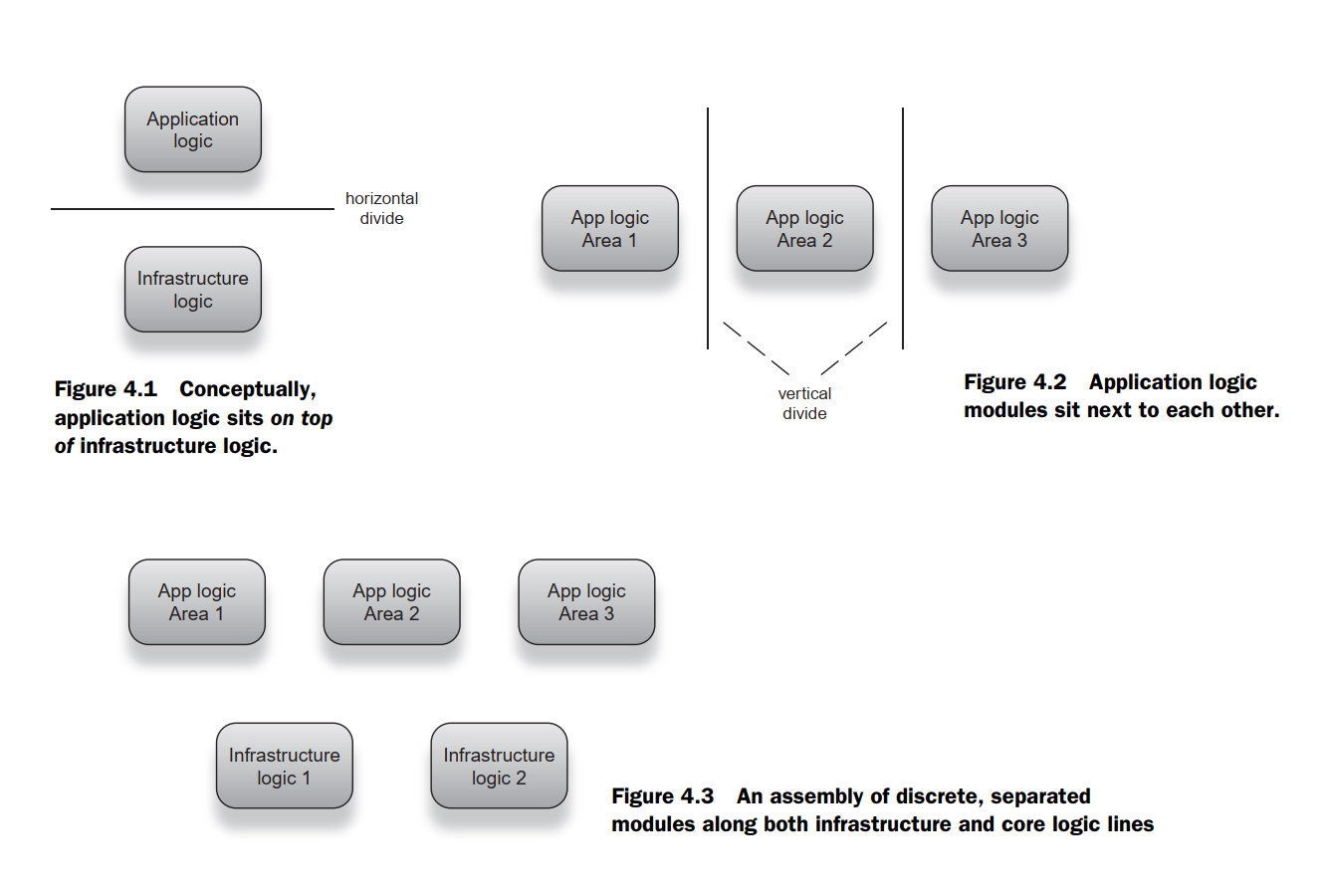
a) It prevents any external agent (like the injector) from reaching its dependencies. By preventing any external agent from reaching its dependencies, not only does it prevent an injector from creating and wiring them, it prevents a unit test from substituting mock objects in their place.
b) It allows for only one particular structure of its object graph (created in its constructor). By deciding its own dependencies, Emailer prevents any variant of them from being created. This makes for poor reuse and a potential explosion of similar code, since a new kind of Emailer would have to be written for each permutation
c) It is forced to know how to construct and assemble its dependencies.
d) It is forced to know how to construct and assemble dependencies of its dependencies, and so on ad infinitum.
- When a dependent is inextricably bound to its dependencies, code is no longer testable. This, in a nutshell, is tight coupling. Tight coupling also means that we have opened the door in the iron wall separating infrastructure from application logic - something that should raise alarm bells on its own.
- What is the difference between loose coupling and tight coupling in the object oriented paradigm? on SO.
- What is the point of having every service class have an interface? on SE.
ArrayList instead of a
HashSet, we would have to change the type of the dependency being passed in into the constructor.
Collection), the code
loses any awareness of the underlying data structure and interacts with it only through an interface.
a) Once bound, a key provides instances of its related object until rebound.
b) When you rebind a key, all objects already referencing the old binding retain the old instance(s).
c) Rebinding is very closely tied to scope. A longer-lived object holding an instance of a key that has been rebound will need to be reinjected or discarded altogether.
d) Rebinding is also tied to lifecycle. When significant dependencies are changed, relevant modules may need to be notified.
e) Not all injectors support rebinding, but there are alternative design patterns in such cases.
- It encapsulates any infrastructure logic and can be used in place of the original dependency with no impact to client code. A change in the binding is signaled to the adapter(s) via a rebinding notification, and the adapter shifts to the new binding. While this is a robust and workable solution, it is fraught with potential pitfalls and should be weighed carefully before being embarked upon.
- There is a difference between hot-deploy and hot-swap as mentioned in this blog post. This SO answer goes into details about how hot-deploy is done.
- This is a SO answer about how hot-swap works.
- One very simple solution is to maintain both object graphs and simply flip the switch when you need to move from one object graph to another. Here the method rebind() controls which dependency LongLived uses. At some stage in its life, when the rebinding is called for, you need to make a call to rebind(). The problem with this approach is that we end up mixing infrastructure logic with our application logic.
- // TODO: Add text in detail about what Adapter Pattern is, and how it actually works.
- Adapter pattern on Baeldung
- Adapter pattern on Refactoring
Singleton. This was to make sure that the
same DependencyAdapter that is being injected into the LongLived class is the same one on which we are calling the rebind() method in the test class.
If you remove the Singleton declaration, then the rebind is called on a different instance of DependencyAdapter, and hence both calls of the
compute() method end up being called on the DependencyA instance.
- One interesting feature of this is the use of a Rebindable role interface. The control logic for dynamic rebinding is thus itself decoupled from the "rebinding" adapters. All it needs to do is maintain a list of Rebindables, go through them, and signal each one to rebind() when appropriate. (Question: What?). Rebinding of the key associated with Dependency is now completely transparent to LongLived - and any other client code for that matter.
- Picture, because why not:
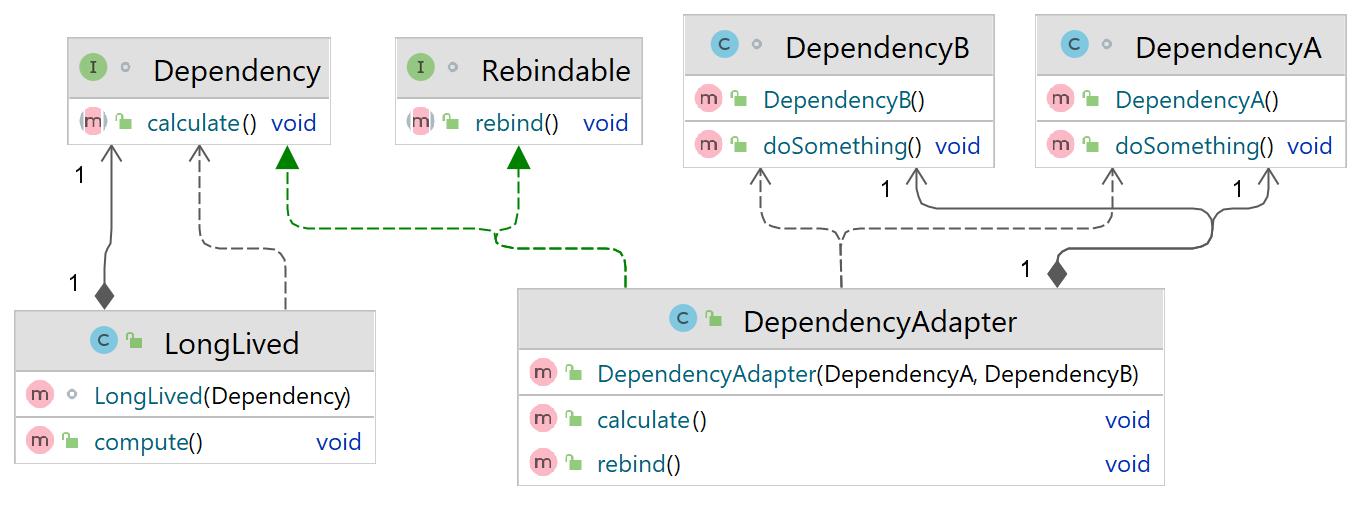
- This has some benefits:
a) It lets the injector manage the latent state of your objects
b) It ensures that your services get new instances of dependencies as needed
c) It implicitly separates state by context (for eg. two HTTP requests specifies two different contexts). This means that code working in a context is oblivious to that context. It is the injector's responsibility to manage these contexts.
d) It reduces the need for state-aware application logic
a) Provides new instances transparently
b) Is managed by the injector
c) Associates a service (key) with some context
- The first two points are self evident. But the last one is not. It's not even true. It is difficult to point out what is the scope that no-scope represents.
- Consider the example that we looked at above. We saw that we could alter the scopes of the objects without making any changes to the objects themselves. To be more precise, the family.give() sequence looked exactly the same for both the singleton as well as the no-scope setup. In that example, we equated the scope of a toothpaste with a bathroom context, and said that each instance of bathroom gets its own instance of toothpaste. But that is not entirely correct.
- Suppose if Charlie wanted to brush his teeth twice daily. In that case, when we asked for a toothpaste, he would have received a completely new instance of it. So now we would have had three instances of bathrooms, but four instances of toothpastes.
- This means that no scope cannot be relied on to adhere to any conceptual context. No scope means that every time an injector looks for a given key (one bound under no scope), it will construct and wire a new instance.
- You can think of no-scope as a split-second scope where the context is entirely tied to referents of a key.
- This becomes very useful when you are trying to inject dependencies in a long-lived object, like we did in the Granny eating example using Provider Pattern here. There, Apple was no-scoped.
- Guice and Spring differ in nomenclature with regard to the no scope. Spring calls it as the prototype scope, the idea being that a key (and binding) is a kind of template (or prototype) for creating new objects.
- Recall in this section in Chapter 3 where we used prototype instances of the objects.
- It is important to emphasize this last point, since it is possible for multiple injectors to exist in the same application. In such a scenario, each injector will hold a different instance of the singleton-scoped object. This is important to understand because many people mistakenly believe that a singleton means one instance for the entire life of an application. In dependency injection, this is not the case.
- On the other hand, in the case of a Singleton scoped binding, we can establish a context quite easily. A singleton's context is the injector itself. As long as the injector exists, the singleton object will exist as well. There is a small subtlety here that the scope is one singleton per injector, not per application. If your application has multiple injectors, each of those injectors will hold a separate/distinct reference of the singleton object. Refer the section on Singleton scope here for details.
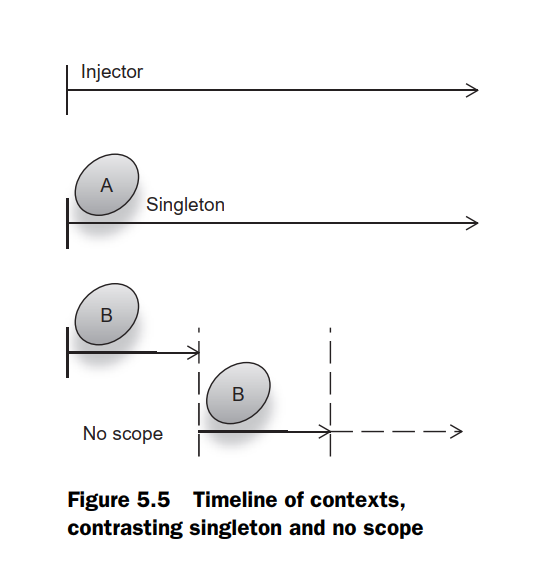
- Services that are stateless (in other words, objects that have no dependencies or whose dependencies are immutable) are good candidates.
- In the scenario where there are no states to manage, either of prototype or singleton scopes can be used. Singleton does have some advantages over prototype in these scenarios:
a) Objects can be created at startup (sometimes called eager instantiation), saving on construction and wiring overhead.
b) There is a single point of reference when stepping through a debugger.
c) Maintaining the lone instance saves on memory (memory complexity is constant as opposed to linear in the case of no scoping)
- Remember the singleton litmus test: Should the object exist for the same duration as the injector?
- This is how we would create Singleton scoped beans in the case of Spring. Note that we can also use two different bean names for the same class. (Using camera.basement and camera.penthouse for the same class SimpleCamera).
- We changed the xml so that the two beans are now defined as singletons.
Singleton. This means that the object associated with each of [MasterTerminal, RoofMaster] and [MasterTerminal, BasementMaster] keys will be
unique.
- This is different from the conventional "Singleton Design Pattern" that we see being used in books which defines a more absolute singleton in the sense that there can always be exactly one instance of a class in an application. This is often considered as an anti-pattern.
- Singleton objects are shared even between injectors and can cause a real headache if you are trying to separate modules by walling them off in their own injectors.
- Singleton objects bad, singleton scoping good. Singleton objects make testing difficult if not impossible and are antithetical to good design with dependency injection. Singleton scoping, on the other hand, is a purely injector-driven feature and completely removed from the class in question.
- Singleton scope is thus flexible and grants the usefulness of the Singleton antipattern without all of its nasty problems.
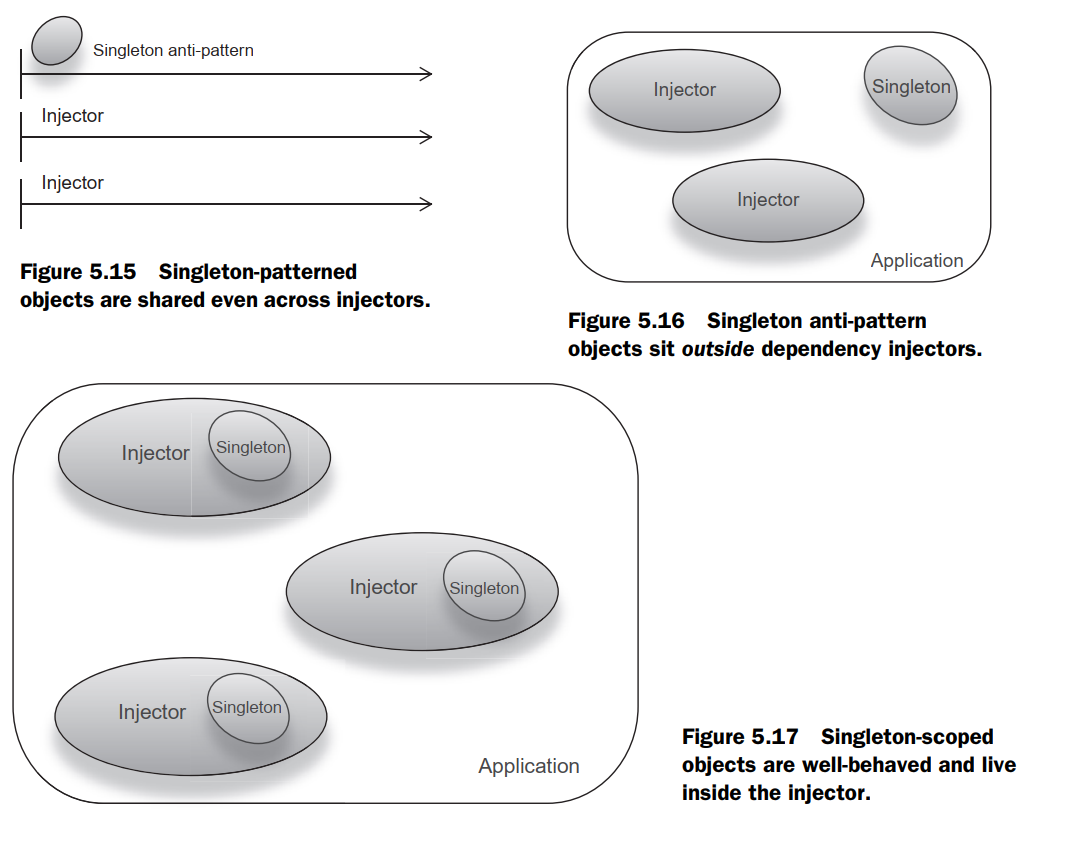
- TODO.